Tvorba a aktualizace datových číselníků
podplukovník Ing. Frantiąek RU®IČKA, VÚ 8860 Belgie
Úvod
Informace, data. Na kvalitě, aktuálnosti a dostupnosti informací jsou v současnosti závislé veąkeré oblasti naąí činnosti. Řazení v logické struktuře od obecných skupin ke konkrétní a podrobné informaci je poľadavek, vycházející z potřeby rychlého nalezení poľadované informace. Příkladem můľe být program kin na Internetu, kdy lze lístky do kina rezervovat přes zvolené město, kino a čas nebo přes ľánr a název hledaného filmu. Funkčnost informačních systémů, které jsou zaloľeny na sběru, aktualizaci a uľivatelských výstupech informací (v tomto případě raději dat), je závislá na kvalitě jejich řazení. Vąechna taková data jsou řazena více či méně pomocí číselníků dat.
Typickým představitelem číselníku je telefonní seznam, kde je kaľdý účastník telefonní sítě identifikován jménem, bydliątěm a jedinečným, neopakovatelným telefonním číslem. Daląím praktickým příkladem je seznam měst a obcí s jejich názvy a poątovními směrovacími čísly (PSČ). V rezortu obrany by jako příklad číselníku mohl slouľit seznam vojenských útvarů a zařízení (VÚZ).
Terminologie
Úvodem je nutné vysvětlit základní(1) terminologii a její obsah. Samozřejmě vychází z obecně platných a zaľitých konvencí, např. v [1], [2].
Uspořádanou kolekci dat s určitou strukturou a za určitým účelem lze nazvat databází. Součástí databáze bývá i software, který umoľňuje manipulaci s daty a přístup k nim, nazývaný systém řízení báze dat. Existuje celá řada typů databází, ten nejroząířenějąí a nejmodernějąí typ je relační databáze.
Tabulka |
Základní část databáze, s nejméně jedním sloupcem a dvěma řádky shromaľďuje logicky související údaje. Pokud se rozhodneme pouľít úvodního příkladu s vojenskými útvary a zařízeními, budou v tabulce údaje o jednom typu objektu - VÚZ. Pro lehčí orientaci je nutné tabulku pojmenovat, např. ,,VUZ". |
| Řádek (záznam) | V řádcích tabulky jsou jednotlivé VÚZ a údaje k nim vztaľené. Kaľdý řádek je v celém rozsahu jedinečný, neopakuje se. |
| Sloupec (poloľka, atribut) | V záhlaví tabulky (první řádek tabulky) je jednoznačně uvedeno, jaký atribut vyjadřuje (popisuje) - na příkladu VÚZ jsou to: ,,název VÚZ", ,,číslo VÚZ", ,,posádka VÚZ" a daląí, např. ,,nezbytná" ,,poznámka". |
Vąe se pokusí přiblíľit tabulka č. 1.

Tabulka č. 1
Obsah jednotlivých poloľek (atributů) by měl splňovat nějaká, předem stanovená kritéria. Tam, kde je očekávaná číselná hodnota, měla by se číselná hodnota také nacházet. Tam, kde je očekáván název útvaru a vojenského zařízení, nemají místo zkratky, zkomoleniny a ani dodatečné, neočekávané informace, např. o posádce, čísle VÚZ a daląí. Nejvhodnějąí varianta je uvádět hodnoty v jednotlivých poloľkách a v záznamech výběrem z uzavřeného mnoľství informací, vhodně řazených v jiné tabulce - datovém číselníku.
Definice datového číselníku by mohla znít tak, ľe se ,,jedná o mnoľinu věcně souvisejících a standardizovaných jedné a více poloľek, formálně vyjádřených pomocí textu nebo řady číslic, s jednoznačnou identifikací kaľdého záznamu, sestavených v tabulce". Slouľí ke sjednocení zpracovávaných podkladů, zpravidla formulářů (písemných nebo elektronických) a umoľňuje hromadné elektronické zpracování dat. Standardnost poloľek spočívá v jednotnosti (struktury, formy atd.).
Je nutné nějaký číselník vytvářet?
Prvním předpokladem pro vznik jakéhokoli datového číselníku (dále jen číselník) je nutnost jeho vzniku. Jinými slovy, číselník dat je nástrojem k vytvoření takové struktury dat, která slouľí poľadovanému (předpokládanému) účelu, tj. např. evidence, vyhodnocení, plánování a jiné podklady k rozhodování nebo jiné činnosti.
Dejme tomu, ľe je nutné sledovat počty personálu po vojenských útvarech a zařízeních. Nutností je tedy vytvořit seznam vojenských útvarů a zařízení, kterým bude přiřazován počet jejich přísluąníků.

Tabulka č. 2
Zjednoduąená tabulka s evidencí počtu personálu můľe mít podobu podle tabulky č. 2:
Tento příklad je moľné pouľít jako základ pro sběr dat pro různé účely. Je nutné si ovąem uvědomit, ľe byl konstruován za jistým účelem a dodatečné poľadavky sniľují pouľitelnost příkladu číselníku. Chybí např. daląí informace o vojenském útvaru (posádka, uvedení místa v organizační struktuře rezortu MO atd.) a také pouhý součet personálu nemusí být dostatečný (pravděpodobně by bylo vhodné počty personálu uvádět po skupinách - vojáci a občanątí zaměstnanci nebo jeątě podrobnějąí, po hodnostech nebo hodnostních sborech).
Dodatečně vznáąené poľadavky jsou pro posouzení věrohodnosti a vyuľitelnosti zpracovaných dat naprosto kritické. Účelnost a objektivnost takových poľadavků je běľně těľké posoudit, v praxi často záleľí jen na umístění tvůrce a posuzovatele dodatečných poľadavků v organizační struktuře organizace.
Řeąit dodatečně vznáąené poľadavky opakovaným sběrem doplněných dat je nejen časově náročné opatření, ale hlavně zpochybňuje celý proces, pro který byla data zpracovávána.
Platí tedy, ľe jedním z hlavních předpokladů pro vytvoření kvalitního (tj. relevantního a stabilního) číselníku dat je předběľná podrobná systémová analýza vazeb a struktury pouľívaných dat nejen v průběhu daného procesu, ale také včasné definování potřebné struktury dat na vstupu a výstupu procesu pouľitelné pro daląí, navazující procesy.
Úroveň podrobnosti číselníku
Při tvorbě číselníku je potřebné zohlednit potřebnou úroveň detailu (kolik informací a jak podrobné informace je nutné zpracovat). Je nutné si uvědomit jednoduchou skutečnost, ľe podrobnost detailu na vstupu (sběru, zahájení procesu) se NEMUSÍ nutně rovnat úrovni detailu na výstupu (vyhodnocení, ukončení procesu). Dochází zpravidla k určitému stupni zobecnění agregace dat podle obsahu jednotlivých datových poloľek. Optimální je disponovat několikastupňovou agregací, ve výąe uváděném příkladu by to mohly být počty personálu od jednotlivých útvarů a zařízení, brigád, velitelství a celkově za rezort MO.
Jiľ v počátku tvorby číselníku je nutné promyslet důsledně úroveň detailu číselníku a nalezení optimální míry mezi podrobností informace, která je poľadovaná a přitom zbytečně nezatěľuje zpracovatele.
Identifikace jednotlivých záznamů číselníků
Kaľdý záznam v číselníku je moľné označit identifikátorem, který ulehčuje uľivatelům orientaci v číselníku a slouľí pro jednoduąąí identifikaci např. dlouhé textové poloľky. Tento identifikátor není povinný, ale lze ho výhodně pouľít při seskupování jednotlivých záznamů do logických skupin. Je moľné označit poloľku jakoukoli alfanumerickou kombinací znaků. Prioritním předpokladem, limitujícím funkčnost celého číselníku, je JEDINEČNOST kaľdého záznamu v číselníku (resp. identifikátoru, pokud je pouľitý). Jako fatální selhání je moľné označit některé publikované číselníky v rezortu MO ČR, které obsahují více stejných identifikátorů záznamů při odliąném věcném obsahu.
Bylo jiľ zdůrazněno, ľe identifikátor není povinný, prioritně má slouľit k jednoduąąí orientaci v poloľkách číselníku. Paradoxně je moľné nalézt číselník (fiktivní příklad) číselných velikostí výstroje s identifikátory, které jsou odliąné od čísel velikostí. Takľe personál porovnáním s inventurní sestavou a převodníky ověřuje, kolik mají výstroje 23505 ve velikosti XsW. Srozumitelnějąí by jistě bylo poloľku 23505 přejmenovat na ,,koąili s krátkým rukávem" a velikost XsW na velikost ,,43". Jednoduąe, materiálové, finanční a personální sestavy dat lze tvořit čitelné, či srozumitelné pro vąechny uľivatele. Není přece nutné vytvářet nový, tajuplně zaąifrovaný jazyk ...
Délka identifikátoru závisí na platformě, kde je uľíván (Windows, Linux apod.) a na pouľitém obsluľném software. Na platformě Windows(2) je k dispozici textový identifikátor v délce 2 miliardy znaků, v případě číselného identifikátoru(3) je maximální hodnota 18 446 744 073 709 551 615 (více neľ 18 trilionů).
Navzdory tomu je opakovaně uváděn poľadavek na omezení délky poloľky např. v [3] a [4], kdy se nejčastěji stanovuje délka poloľky do 32 znaků nebo v případě textové poloľky do 255 znaků. Tento poľadavek je technicky zastaralý, věcně neopodstatněný a vychází z historického vývoje databází.
Historické ohlédnutí
Obrázek č. 1
V první polovině 80. let byl uveden na trh program nazvaný dBASE. Byl vyvinut pro osmibitové počítače a na dlouhou dobu byl ve své kategorii jediným produktem. Pravděpodobně nejpovedenějąí a nejroząířenějąí byla verze dBASE III Plus, pro kterou také existovala česká nadstavba (podobná jako na obr. č. 1).
Úspěch dBASE III Plus asi spočíval v tom, ľe při své prokazatelné jednoduchosti poskytovala rozumné moľnosti přístupu k datům (pro zrychlení přístupu se pouľívalo indexů), dostatečně bohatou ąkálu tiskových sestav a pro programování i jednoduché moľnosti ladění.
Jedním z nedostatků dBASE III Plus byla její pomalost. Bylo to hlavně způsobeno tím, ľe program v programovacím jazyce byl interpretován přímo ze zdrojového textu (převzato z [5]).
Navíc měl mnoho omezení, např. názvy poloľek mohou být dlouhé maximálně 32 znaků, poloľka dlouhá maximálně 255 znaků a přesnost desetinných čísel byla omezena na 20 míst. Jedním z nejváľnějąích omezení je to, ľe vąechny poloľky mají pevnou délku(s vyuľitím [6]).
Na svou dobu (1978-1988) byly ovąem produkty dBASE revolučním krokem pro management databázi.
Aktualizace číselníku
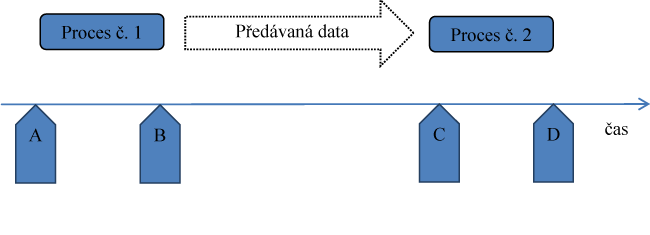
Schéma č. 1
Daląím faktorem, který ovlivňuje kvalitu a tedy pouľití číselníku, je jeho aktualizace. Aktualizaci číselníku lze obecně chápat tak, ľe se vąechny záznamy a poloľky číselníku porovnají s nějakým stavem (např. stavem k nějakému datu apod.), vyhodnotí se odchylky a po posouzení příčiny a závaľnosti odchylky se číselník upraví.
Existuje určité, ovąem naprosto kritické omezení. Spočívá v dodrľení časové souslednosti procesů, které číselník pouľívají, nelze ho tedy bez negativních důsledků měnit v průběhu procesu ani mezi navazujícími procesy, ale aktualizace by měla být prováděna mimo procesy, nejlépe tedy před a po jeho pouľití, tedy pokud lze nalézt nějakou ucelenou etapu souslednosti procesů.
Jako příklad lze uvést dva závislé procesy, které sdílejí stejný číselník (schéma č. 1). V rezortu obrany ČR můľe jít například o proces plánování a rozpočtování, investiční a akviziční procesy nebo výstavbu sil a evidenci personálu. Pokud na časové ose je proces č. 1 ohraničen mezi body A-B a proces č. 2 mezi body C-D, v období B-C dochází k předávání, verifikaci (moľná i restrukturace) a přípravě k pouľití daląího, navazujícího procesu.
Pokud dojde k úpravě číselníku mezi body:
- A-B, ovlivní to jen proces č. 1;
- B-C, jsou data z procesu č. 1 pro proces č. 2 pouľitelná jen částečně;
- C-D, jsou data z procesu č. 2 pouľitelná jen částečně (např. kvůli vyhodnocení);
- D a dále, dochází alespoň k částečné ztrátě kontinuity historické báze dat, tzn., nelze relevantně vyhodnotit po sobě jdoucí cykly procesů.
Není aľ tolik podstatné, z jakých důvodů dochází k úpravě číselníků (změna zákona, vyhláąky, rozhodnutí politické reprezentace), téměř vľdy dochází k negativním jevům.
V této souvislosti je třeba říci, ľe správce číselníku (to je pověřená sloľka rezortu obrany, která daný číselník spravuje, tj. můľe ho vytvořit, aktualizovat, uľívat a poskytovat jiným sloľkám) nemusí odpovídat za vąechny procesy, které číselník uľívají. Pokud není nastavena vhodná úroveň komunikace, dochází zpravidla k jevům, kdy se navzájem vąechny procesy se sdíleným číselníkem negativně ovlivňují.
Z daląích variací moľných stavů lze vybrat ten, pokud oba procesy č. 1 a č. 2 pouľívají vlastní číselníky, ovąem logicky propojené. Pokud tedy správce procesu č. 1 a přísluąného číselníku ho nějakým způsobem upraví, správce procesu č. 2 a přísluąného číselníku má na výběr moľné varianty:
- upravit (aktualizovat) vlastní číselník a snaľit se udrľet datovou vazbu mezi procesy č. 1 a 2;
- ponechat číselník neaktualizovaný a udrľet vlastní historickou bázi dat vlastních datových řad bez vazby na proces č. 1;
- jiné řeąení.
Lze tedy odvodit, ľe správce číselníků by měl provádět aktualizaci s ohledem nejen na proces, za který zodpovídá, ale také s ohledem na vąechny procesy, které číselník uľívají se zřetelem na moľné daląí dopady. Protoľe zpravidla platí, ľe kaľdý proces pracuje s nějakými vstupy a měl by tvořit pouľitelné výstupy.
U jednotlivých poloľek číselníku můľe dojít k několika změnám:
- zruąení poloľky;
- změna poloľky sloučením s jinou poloľkou číselníku;
- změna poloľky rozloľením do více poloľek;
- vytvoření nové poloľky číselníku.
Důsledky jednotlivých změn mohou být různé. Jako součást datové věty (coľ je logická posloupnost poloľek různých číselníků s určením mnoľství zdrojů - finančních, věcných, lidských) má zruąení poloľky číselníku za následek definitivní ztrátu alokovaných zdrojů.
Pří sloučení více poloľek nevzniká v období pouľití závaľný problém. Dokonce ho lze pouľít kdykoli i v průběhu procesu.
Při rozloľení poloľek na několik poloľek by mělo dojít k rozloľení zdrojů na tyto poloľky, původně přiřazených jedné poloľce číselníku. Bez informace, jak zacházet se zdroji alokovanými k původní poloľce, dochází ke ztrátě zdrojů nebo jejich chybné alokaci.
Nová poloľka číselníku nemá alokované zdroje, a jsou na ní alokované zdroje, které byly v předeąlých procesech nebo cyklu alokovány jinde.
Před kaľdou změnou číselníku je nutné si ovąem také uvědomit, ľe dochází ke ztrátě kontinuity historické báze dat. Tzn., ľe jiľ nepůjde bez určitého zkreslení porovnat vývoj alokace zdrojů v jednotlivých řadách dat v několika obdobích na stejných poloľkách a kaľdá změna číselníku způsobí nějakou odchylku. Nelze tedy zcela souhlasit s častými, nepravidelnými úpravami číselníků uľívaných v rezortu MO bez dostatečného ujasnění negativních dopadů.
Ponechání jiľ neplatné poloľky v číselníku, např. z důvodu zachování datové řady, není vhodné řeąení. V roce 2006 bylo moľné v číselníku vojenských útvarů jednoho z klíčových dokumentů rezortu MO nalézt vojenský útvar, který byl při rozdělení republiky (1993) redislokován na Slovensko a tam v roce 1995 zruąen. Protoľe byl v číselníku nadále, alokovaly se na něj nadále přísluąné zdroje (reálný případ).
Jakýkoli zásah do jiľ uľívaného číselníku má negativní dopady, proto je nutné kaľdou úpravu číselníku provést po vyhodnocení těchto dopadů.
Pokud dojde ke změně číselníku dat, je nutné takovou změnu vhodně evidovat.
Kontinuita historické báze dat
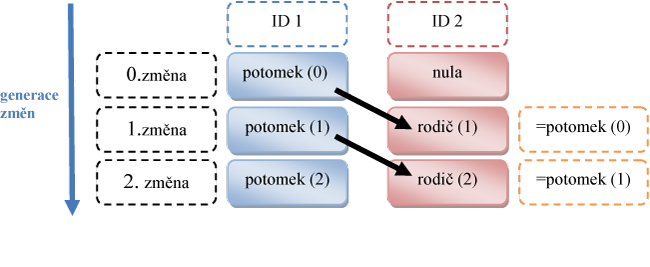
Schéma č. 2
Vhodným řeąením, jak udrľet kontinuitu historické báze dat (např. číselník dat), je sledování postupných změn. V jednotlivých generacích úprav se k novým záznamům přidá odkaz na předchozí stav (rodiče) a rodičovskému záznamu se přidá odkaz na nový záznam (potomka). Celý algoritmus je přehledněji znázorněn na schématu č. 2.
Zabezpečení vazby mezi jednotlivými ,,generacemi" jednotlivých stavů (řazených chronologicky) je úkolem obsluľného software podle uvedeného algoritmu.
Datové rozhraní
Dosud jsou v rezortu MO ČR (a jistě se nejedná o nějaký výjimečný případ ve státní správě ČR) budovány podpůrné informační systémy (IS), které nezohledňují navzájem poľadavky na datové vstupy (včetně jiľ zmíněného příkladu s výměnou číselníků). Dochází pak někdy k paradoxu, ľe vstupy se do IS přepisují RUČNĚ z tiątěných sestav jiného IS. Vzájemná propojitelnost informačních systémů v mnohých případech závisí jen na interpersonálních vztazích zástupců jednotlivých sloľek, řídících ,,své", na podporu své činnosti vybudované, podpůrné IS - v pozitivních i negativních dopadech. Příkladem z praxe můľe být předávání souboru s výstupními sestavami v ,,elektronické podobě" ve formátu PDF(4).
Při výměně dat (viz část ,,Aktualizace číselníku") je důleľité dodrľet ,,pouze" dvě základní podmínky:
- validita dat - pod tímto souhrnným označením lze chápat
- věcnou správnost informací;
- aktuálnost.
- formální podoba dat, která zahrnuje dodrľení dohodnuté struktury dat, jejich formátu ve správných metrických jednotkách(5), v případě potřeby doplněné textovým popisem. Důleľitým aspektem je včasnost (dodrľení termínu) předání dat.
Mělo by být zřejmé, ľe po předání dat by předaná data NEMĚLA být dodatečně poskytovatelem dat měněna.
Na formátu souboru dat jiľ tolik nezáleľí a není podstatné, jestli půjde o prostý text, soubor MS Access, MS Excel nebo roząířený XML formát [7]. Podstatné je, aby poskytovatel a příjemce dat disponovali vhodným softwarovým nástrojem pro export/import dat z/do IS.
Relační databáze
Poměrně často jsou v rezortu MO distribuovány a uľívány číselníky, které obsahují více věcně nesouvisejících atributů.
Takovým je např. číselník cílů a úkolů, které jsou dále přiřazeny jednotlivým VÚZ. U takového provedení číselníku je zvýąená pravděpodobnost nutnosti aktualizace, jelikoľ při změně jednoho atributu (cíl, úkol nebo VÚZ) se musí aktualizovat celý tento kombinovaný číselník.
Jiľ při tvorbě číselníku by se mělo přihlíľet k jeho snadné údrľbě (aktualizaci). Na myąlence umístění informace v několika samostatných tabulkách, propojených vzájemně vztahy (relacemi) - relační databáze [8]. Změnu číselníku lze tak provádět jen na jednom místě. Minimalizuje se tím čas potřebný k aktualizaci a moľnost vzniku chyb.
Nejdříve je nutné doplnit některé pojmy a jejich význam:
Primární klíč |
Primární klíč je atribut, jehoľ hodnota je pro kaľdý záznam jedinečná. Můľe to být např. rodné číslo, u kterého je zaručeno, ľe je má kaľdý občan České republiky jedinečné. U čísla VÚZ není zřejmé, jestli je jedinečné, a proto lze primární klíč i automaticky generovat. Často se tento identifikátor (zauľívaný název) ,,logicky" konstruuje jako daląí atribut tabulky. Např. vąechny útvary podřízené Velitelství XY musí začínat číslicí 1 a tvoří se tak daląí ,,ąifrovaný" jazyk. Řazení jednotlivých záznamů do skupin je moľné tvořit daląími atributy. |
Cizí klíč |
Cizí klíč je atribut, který slouľí jako odkaz na jinou tabulku a obsahuje tedy primární klíče jiné tabulky. Pokud se tabulka účastní více vztahů s ostatními tabulkami, můľe obsahovat více cizích klíčů. |
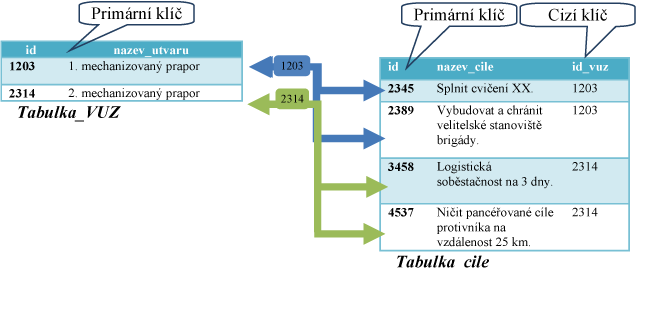
Schéma č. 3
Mezi tabulkami mohou existovat různé typy vztahů. Nejčastějąí vztah je 1:N, kdy jednomu záznamu jedné tabulky je přiřazeno několik záznamů druhé tabulky. Z důvodu kompatibility jsou upravené názvy atributů a tabulek tak, aby neobsahovaly diakritická znamínka a mezery, mezery mezi slovy jsou nahrazeny podtrľítkem (,,_"). Lze tak bez problémů v databázi procházet data podle jména tabulky a jejího atributu.
Na schématu č. 3 je zřejmá vazba 1:N mezi jednotlivými záznamy v tabulkách podle jednotlivých klíčů (primárních a cizích). Jeden útvar má tak přidělen pomocí vazby mezi tabulkami jeden a více cílů.
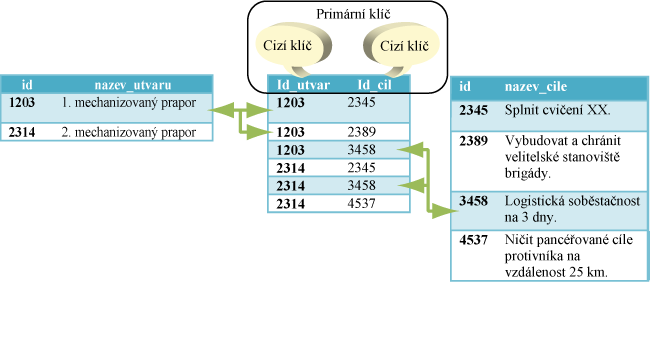
Schéma č. 4
Jiným typem vazby mezi tabulkami relační databáze je vazba M:N (schéma č. 4). S úpravou výąe uvedeného příkladu se jedná o vztah, kterým je vyjádřeno, ľe jeden útvar můľe mít přidělených jeden a více cílů a naopak, jeden cíl můľe být realizován jedním a více útvary.
Vloľením převodní tabulky ,,Tabulka_VUZ_Cil" se vąechny vztahy zjednoduąí na vztahy 1:N. Primární klíč je v této tabulce tvořen jedinečnou kombinací cizích klíčů z tabulek ,,Tabulka_VUZ" a ,,Tabulka_Cile". Lze tak identifikovat, které útvary se podílejí na realizaci cílů a jaké cíle jsou přidělené vojenskými útvary a zařízeními.
V praxi se běľný uľivatel s relačními tabulkami setká jen ve formě generovaného výstupu. Pro řízení procesu je ovąem nezbytné si uvědomit, ľe softwarová podpora můľe být vytvořena aľ po systémových principech tvorby, řízení a vyhodnocení procesu, přičemľ kaľdá změna znamená dodatečné úpravy podpory procesu(6). Větąinou jde o přirozený a ľádoucí vývoj (progres, evoluce), někdy se naopak jedná o zřejmé pochybení jiľ v samotném procesu s veąkerými věcnými, finančními a časovými následky.
V tomto příkladu jsou jednotlivé identifikátory (primární a cizí klíče) pouľity pouze za účelem vysvětlení vazby (relace) mezi tabulkami. Standardní uľivatel (či spíąe spotřebitel) se s nimi za normálních okolností nesetká.
SQL
Jeden z nástrojů, kterým lze manipulovat s relační databází, je programovací jazyk SQL (Structured Query Language). Jazyk SQL je programovací jazyk připomínající angličtinu, který je srozumitelný pro databázové programy. Je definován normou ISO/IEC 9075. Jazyk SQL je programovací jazyk, který pracuje se sadami údajů a relacemi mezi nimi. Na rozdíl od jiných programovacích jazyků není ani pro začínajícího uľivatele obtíľné jazyk SQL číst a porozumět mu.
Jednoduchý příklad příkazu SQL vyuľívající výąe uvedených relačních tabulek, který načte seznam vojenských útvarů a zařízení, jejichľ jméno obsahuje řetězec ,,mech" (mechanizovaný), můľe vypadat například takto:
SELECT nazev_utvaru
FROM tabulka_VUZ
WHERE nazev_utvaru LIKE "*mech*";
Podrobný popis jazyka SQL je mimo předmět tohoto článku a k daląímu studiu lze doporučit odbornou literaturu, např. [9], [10], [11].
Grafické rozhraní
Na základě praxe lze předpokládat, ľe při vyąąím počtu zpracovatelů podkladů jich celá řada (a zajisté v dobrém úmyslu) vyuľije moľnost zpracování podkladů k vloľení daląích, zpřesňujících údajů - resp. poznámek. Vysoce pravděpodobné je také poskytování podkladů v odliąné formě, zejména u výąe postavených zpracovatelů v hierarchii organizace. Negativním důsledkem je, ľe takové vstupy nelze bez dodatečné opravy vyuľít při hromadném zpracování dat a sniľují jejich věrohodnost.
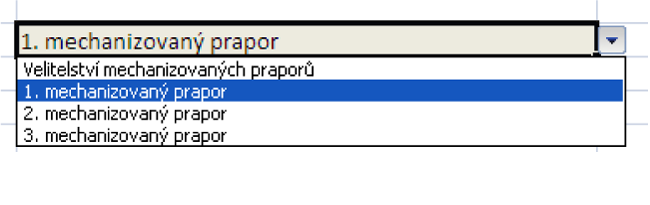
Obrázek č. 2
Chyby způsobené ručně vkládanými vstupy (nejedná se jen o překlepy, ale také o pouľití zkrácených slov, nesprávného názvu atd.) mohou být eliminovány pouľitím vizuálních grafických prvků naplněných předdefinovanými hodnotami z číselníku dat. Takových prvků existuje celá řada, mezi nejčastěji pouľívané vizuální prvky patří ,,rozevírací seznam", známý také pod anglickým názvem - ,,ComboBox" [12] - obrázek č. 2.
Na druhou stranu, jedinečnost některých potřeb, působností nebo úkolů vyľaduje dodatečné upřesnění, prováděné často v různé kvalitě a rozsahu. V případě jedinečných vstupů od uľivatelů vzniká potřeba tyto vstupy dodatečně vyhodnocovat, seskupovat nebo jinak standardizovat. Je výhodnějąí jiľ před sběrem potřeb od uľivatelů umoľnit svou potřebu zařadit do vhodné kategorie (skupiny) v logickém řazení od obecného ke konkrétnímu zařazení potřeby - coľ zase klade vyąąí nároky na tvůrce číselníku dat.
Číselník dat by měl obsahovat vąechny moľnosti a umoľnit tak po jeho pouľití automatizované zpracování dat. Musí ale, v případě neurčitého počtu záznamů nebo poloľek, obsahovat záznam nebo poloľku pro případný nový vstup od uľivatele (nová poloľka, poznámka, daląí, nový apod.).
Původní stručný seznam vojenských útvarů a zařízení můľe být také roząířen o daląí logické doplňující informace. Předně, uvedený seznam by po vyplnění reálných informací a jen málo roząířený podléhal zvláątnímu reľimu utajovaných informací podle nařízení vlády č. 522/2005 Sb., kterým se stanoví seznam utajovaných informací v působnosti jednotlivých ministerstev a musel by být utajován na stupeň ,,V".
Takto roząířený číselník po propojení na data jiľ otvírá daląí moľnosti tvorby výstupů pro analýzy, verifikace, rozhodnutí atd. (záleľí na účelu tvorby číselníku dat).
Závěr
Příspěvek se zabývá dosud obecně nepopsanou oblastí v softwarové podpoře procesů - tvorbě a aktualizaci číselníku dat - ve vąech moľných aspektech. Vychází z několikaleté praxe tvorby číselníků v procesu střednědobého plánování a z prostudování několika veřejně přístupných ,,číselníků dat" jiných procesů. Některé z těchto číselníků obsahovaly podle autora článku řadu kritických, aľ diletantských chyb, které způsobily, ľe takové číselníky dat byly nepouľitelné v jiných procesech, neumoľňovaly aktualizaci a přiměřenou stabilitu (kontinuitu historické báze dat) souvisejících procesů.
Základním východiskem a s vyuľitím odborné literatury je sladěna a pouľita vhodná terminologie.
Za číselník dat se povaľuje mnoľina věcně souvisejících a standardizovaných jedné a více poloľek, formálně vyjádřených pomocí textu nebo řady číslic, s jednoznačnou identifikací kaľdého záznamu, sestavených v tabulce, slouľících ke standardizování podkladů.
Dále, vzniku číselníku dat by měla předcházet analýza se zaměřením na účel a strukturu číselníku dat. Je nutné identifikovat vzájemné vazby na vstupech a výstupech mezi jednotlivými procesy, které číselník dat vyuľívají přímo nebo v odvozené podobě.
Jiľ při tvorbě číselníku dat je nutné pamatovat na pozdějąí nezbytné úpravy s minimalizací pozdějąích nevyhnutelných negativních dopadů. Aktualizaci číselníku dat je věnována značná pozornost se závěrem, ľe nezbytnou aktualizaci číselníku dat je nutné vhodně věcně a časově sladit s navazujícími procesy.
Značná část článku je věnována technické části provedení číselníku. Nemá se jednat o návod, ale o poskytnutí teoretických základů pro přísluąné manaľery a snad i pokus o částečné odstranění ,,pověstí" o technické sloľitosti a z toho vyplývající finanční náročnosti softwarového provedení, vydatně ľivené na jedné straně specializovanými firmami poskytujícími outsourcingové řeąení a elementární neznalostí některých manaľerů, ovlivňující vývoj informačních systémů v rezortu MO ČR.
Informace obsaľené v článku by měly být zohledněny při tvorbě a řízení jakéhokoli procesu, u kterého se předpokládá softwarová podpora. Lze tak předejít řadě moľných problémů s dopady na personální, časovou a finanční náročnost při hledání jejich dodatečných řeąení.
Literatura:
[1] HERNANDEZ, Michael J., VIESCAS, John L. Myslíme v jazyku SQL - Tvorba dotazů. 1. vydání. Grada Publishing 2004. ISBN: 80-247-0899-X.
[2] http://www.kosek.cz
[3] příloha č. 4 Odborné nařízení pro zpracování návrhu státního rozpočtu a střednědobého rozpočtového výhledu v rezortu Ministerstva obrany, čj. 80-34/2010-8201, ze dne 30. dubna 2010.
[4] http://adisepo.mfcr.cz/adistc/adis/idpr_pub/epo2_info/popis_struktury_seznam.faces (popis struktury souborů daňové správy - MF ČR).
[5] http://www.ics.muni.cz/zpravodaj/articles/369.html.
[6] http://www.dbase.com/dBase_Knowledgebase.asp.
[7] http://www.w3.org/XML/.
[8] VIESCAS, John, CONRAD Heft. Mistrovství v Microsoft Office Access 2007. Computer Press 2008. ISBN: 978-80-251-2162-7.
[9] SHELDON, Robert. SQL - začínáme programovat. Grada 2005. ISBN:80-247-0999-6.
[10] GROFF, James R., WEINBERG, Paul N. SQL - Kompletní průvodce. Computer Press 2005. ISBN: 80-251-0369-2.
[11] OPPEL, Andy. SQL bez předchozích znalostí - Průvodce pro samouky. Computer Press 2008. ISBN: 978-80-251-1707-1.
[12] http://msdn.microsoft.com/cs-cz/library/ms754288.aspx.
(1) Ostatní termíny jsou vysvětleny při prvním pouľití (zpět)
(2) Obchodní značka firmy Microsoft pro několik typů operačních systémů (zpět)
(3) Pro programátory: jedná se o typ označený UInt64 (zpět)
(4) (Portable Document Format - PDF) - formát souborů vyvinutý firmou Adobe k uloľení a tisku dokumentů v identickém formátu nezávisle na pouľitém software a hardware. Pro účely předání dat v souboru obsaľených k importu do IS naprosto nevhodné (zpět)
(5) Operace se správnými hodnotami, uváděnými v jedné části např. v Kč a v jiné části v mil. Kč vede zpravidla k fatálním výsledkům (zpět)
(6) Jedná se o teoreticky jednoduchou a logickou konstrukci. Praxe bývá bohuľel odliąná. Autor tohoto článku negativním oponentním posudkem zamezil realizaci dvouletého výzkumného projektu, ve kterém se v první části nakupoval software a v daląí části se posuzovala jeho vhodnost k podpoře procesu, který do té doby nebyl a ani dosud není nastaven a popsán - vąe za několik milionů Kč (zpět)